Speed of Sound Prior Example
The main purpose of this code is to demonstrate how one can fix the prior-likelihood to a constant value and use multinest to sample the prior space log-uniformly. Within this script, one can use the PosteriorAnalysis.pyscript to generate the prior axuiliary data and the prior 95% confidence intervals.
The following block of code will properly import NEoST and its prerequisites, furthermore it also defines a name for the inference run, this name is what will be prefixed to all of NEoST’s output files.
The machinary used within this script and the explanation of them is identical to those found in the Piecewise Polytropic, Speed of Sound, and Tabulated Examples.
[1]:
import neost
from neost.eos import speedofsound
from neost.Prior import Prior
from neost.Star import Star
from neost.Likelihood import Likelihood
from neost import PosteriorAnalysis
from scipy.stats import multivariate_normal
from scipy.stats import gaussian_kde
import numpy as np
import matplotlib
from matplotlib import pyplot
from pymultinest.solve import solve
import time
import os
import neost.global_imports as global_imports
# Some physical constants
c = global_imports._c
G = global_imports._G
Msun = global_imports._M_s
pi = global_imports._pi
rho_ns = global_imports._rhons
# Define name for run
run_name = "prior-hebeler-cs-"
directory = '../../examples/chains'
# We're exploring a speed of sound (CS) EoS parametrization with a chiral effective field theory (cEFT) parametrization based on Hebeler's work
# Transition between CS parametrisation and cEFT parametrization occurs at 1.1*saturation density
speedofsound_cs = speedofsound.SpeedofSoundEoS(crust = 'ceft-Hebeler', rho_t = 1.1*rho_ns)
Below, we define the speed of sound equation of state model, import the J0740 likelihood function, and define the number of stars.
[2]:
# Create the likelihoods for the individual measurements
mass_radius_j0740 = np.load('../../examples/j0740.npy').T
J0740_LL = gaussian_kde(mass_radius_j0740)
# Pass the likelihoods to the solver
likelihood_functions = [J0740_LL.pdf]
likelihood_params = [['Mass', 'Radius']]
# Define whether event is GW or not and define number of stars/events
chirp_mass = [None]
number_stars = len(chirp_mass)
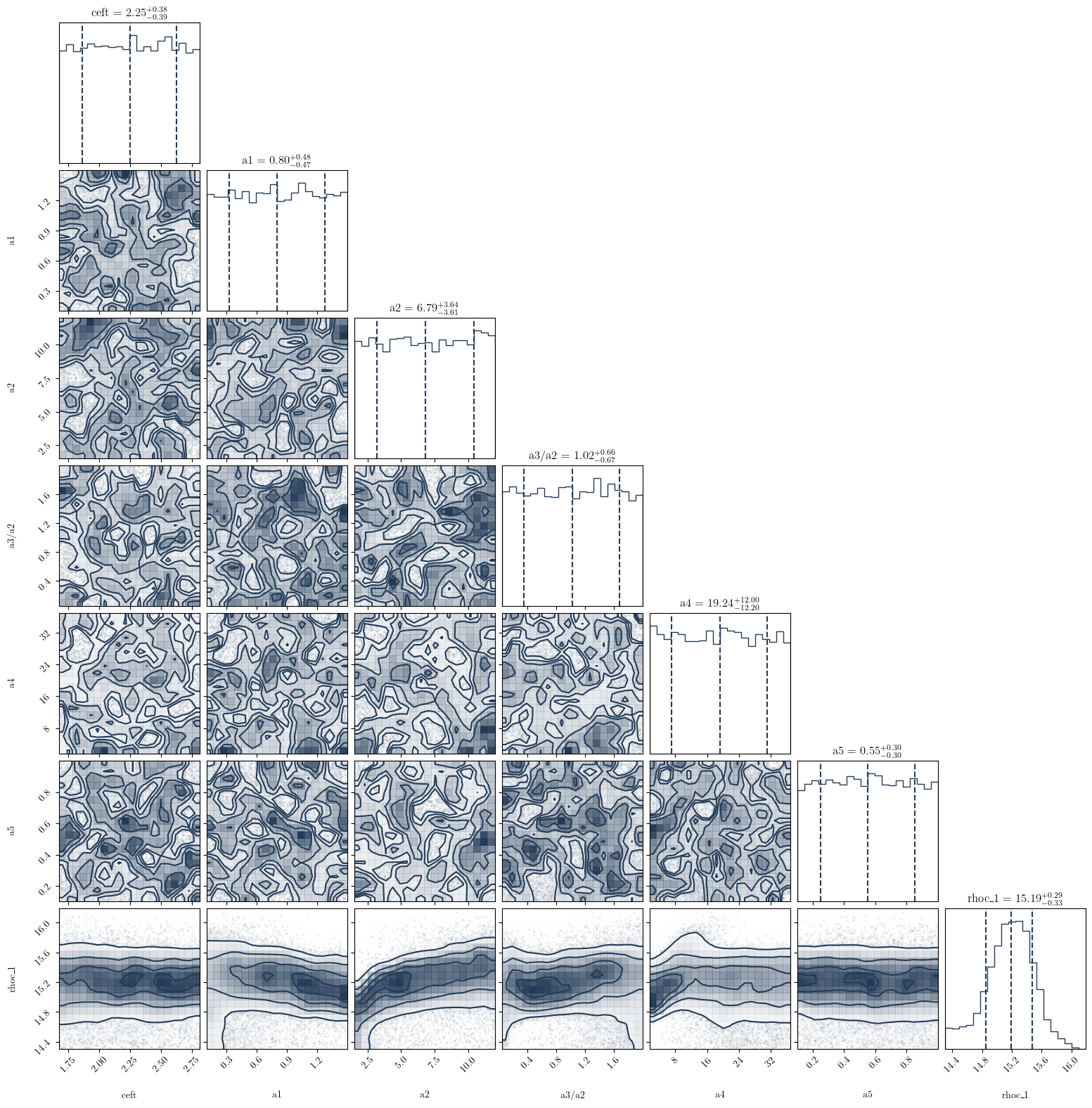
Similar to the posterior analysis tutorials, we define the static parameters (which there are none in this example), define and update the variable parameters for each source (one for this case), and define the prior object. Additionally, we define a prior loglike function, which defines a constant prior log-likelihood value for each sample drawn of each parameter (pseudo_var). This is defined in this way such that each sample has an equal prior likelihood of being drawn, thus we have a
suffciently uniform and non-informative prior for each parameter in the equation of state.
[6]:
# Define variable parameters, same prior as previous papers of Raaijmakers et al
variable_params={'ceft':[speedofsound_cs.min_norm, speedofsound_cs.max_norm],'a1':[0.1,1.5],'a2':[1.5,12.],'a3/a2':[0.05,2.],'a4':[1.5,37.],'a5':[0.1,1.]}
for i in range(number_stars):
variable_params.update({'rhoc_' + str(i+1):[14.6, 16]})
# Define static parameters, empty dict because all params are variable
static_params={}
# Define prior
prior = Prior(speedofsound_cs, variable_params, static_params, chirp_mass)
print("Bounds of prior are")
print(variable_params)
print("number of parameters is %d" %len(variable_params))
# Define likelihood, pseudo_var is required as input because NEoST expects to be able to pass the parameter sample drawn from the prior to be passable to the likelihood
def loglike(pseudo_var):
return 1.
Bounds of prior are
{'ceft': [1.676, 2.814], 'a1': [0.1, 1.5], 'a2': [1.5, 12.0], 'a3/a2': [0.05, 2.0], 'a4': [1.5, 37.0], 'a5': [0.1, 1.0], 'rhoc_1': [14.6, 16]}
number of parameters is 7
Here, we implement multinest to uniformly sample the prior space and for each sample from the prior that it draws it assigns a constant prior log-likelihood value of 1. Note, the greatly increased number of livepoints. This is required because each livepoint terminates after 1 iteration.
[8]:
# Then we start the sampling, note the greatly increased number of livepoints, this is required because each livepoint terminates after 1 iteration
start = time.time()
result = solve(LogLikelihood=loglike, Prior=prior.inverse_sample, n_live_points=10000, evidence_tolerance=0.1,
n_dims=len(variable_params), sampling_efficiency=0.8, outputfiles_basename=f'{directory}/{run_name}', verbose=True, resume=False)
end = time.time()
print(end - start)
*****************************************************
MultiNest v3.10
Copyright Farhan Feroz & Mike Hobson
Release Jul 2015
no. of live points = ****
dimensionality = 7
*****************************************************
Starting MultiNest
generating live points
live points generated, starting sampling
Acceptance Rate: 1.000000
Replacements: 10000
Total Samples: 10000
Nested Sampling ln(Z): **************
Importance Nested Sampling ln(Z): 1.000000 +/- 0.000000
analysing data from ../../examples/chains/prior-hebeler-cs-.txt
ln(ev)= 1.0000000000000036 +/- 1.3411045074462890E-009
Total Likelihood Evaluations: 10000
Sampling finished. Exiting MultiNest
406.4890100955963
[9]:
# Compute auxiliary data for posterior analysis
PosteriorAnalysis.compute_auxiliary_data(directory, speedofsound_cs, variable_params, static_params, chirp_mass, identifier=run_name)
# Make some analysis plots
PosteriorAnalysis.cornerplot(directory, variable_params, identifier=run_name)
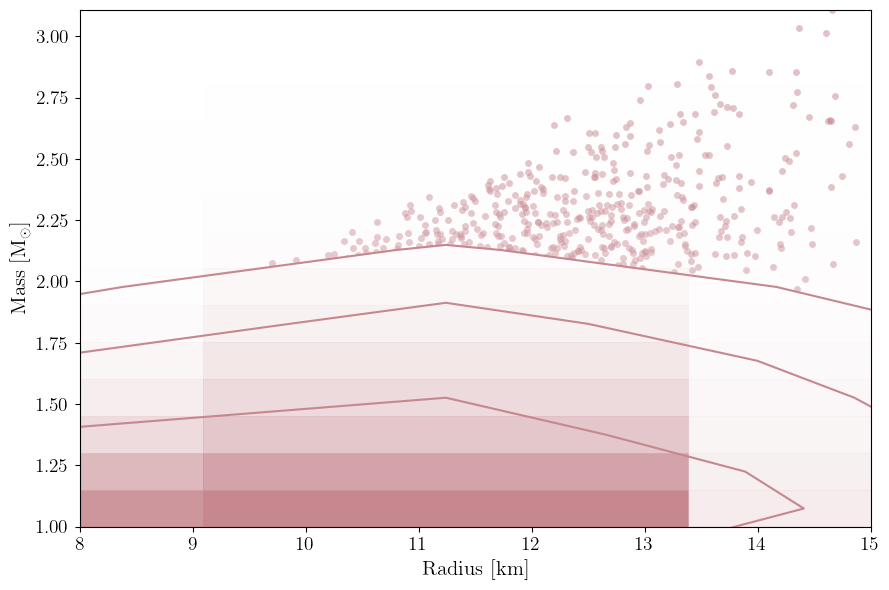
PosteriorAnalysis.mass_radius_posterior_plot(directory, identifier=run_name)
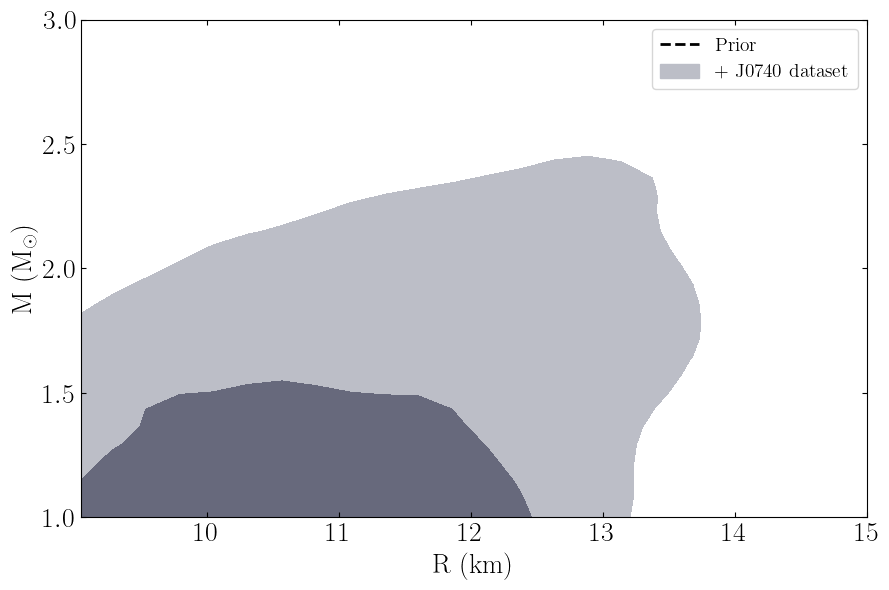
PosteriorAnalysis.mass_radius_prior_predictive_plot(directory, variable_params, identifier=run_name, label_name='+ J0740 dataset')
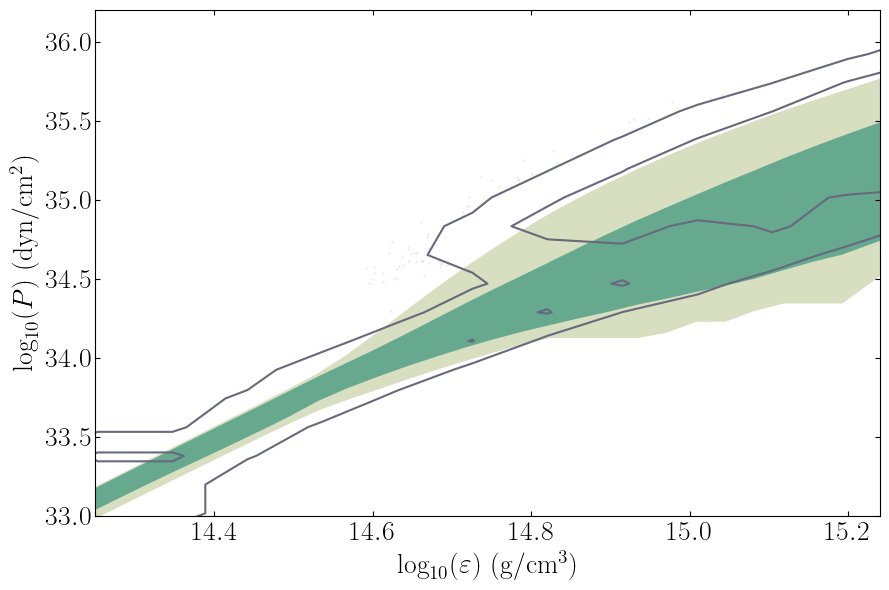
PosteriorAnalysis.eos_posterior_plot(directory, variable_params, identifier=run_name)
Total number of samples is 10000
sample too small for 10000000000000000.00
sample too small for 7129535313794352.00
sample too small for 7758824319047053.00
sample too small for 8443657568728348.00
sample too small for 9188937680019554.00
sample too small for 10000000000000000.00
sample too small for 2.51
sample too small for 2.57
sample too small for 2.62
sample too small for 2.68
sample too small for 2.73
sample too small for 2.79
sample too small for 2.84
sample too small for 2.90